

- cross-posted to:
- world@lemmy.world

You must log in or register to comment.
Liang Wenfeng, DeepSeek’s enigmatic founder, said in a rare interview with Chinese media outlet Waves in July that the startup “did not care” about price wars and that achieving AGI (artificial general intelligence) was its main goal.
Bazingabrainism has reached China

Yea it’s stupid, but I have faith in the CPC to reign them in if what they do starts being counter-productive
Diagnosis: Yudkowsky brain
Prognosis: Terminal
Sure, but this is also what the spokesperson of a company trying to compete with openai would have to say publicly to pander to the customers/sharehoggers, so perhaps their infection isn’t quite as deep as amerikkka’s
I prefer this logic to “We are gonna make “AGI”, keep it locked away and collect rents for the next hundred years and hopefully use it to kick into a new higher gear of imperialist domination”.
Ofc none of these bazingabrains will ever make an “AGI”, but at least deepseek isn’t GriftCo.
But I hate chat bots and hedge funds. So I hope deepseek, Alibaba, openai, m$, etc, all lose. None of this shit is even worth the hardware and electricity it uses.
oof
they caught the crackercranium
its contagious
Fuck AI to the many hells for the shit that it is. However seeing so much money evaporate in these big tech companies is the most hilarious thing I’ve seen in a while.
 We are going to win so much you will be tired of winning
We are going to win so much you will be tired of winningI am going to build the great firewall 10 foot higher!!!
They actually put a little door in the wall so we could learn about healthcare models that don’t bankrupt you for an ambulance ride and also how to make jīdàn gēng.
nice, i was starting to get worried when nvidia stock price started going up again
The plagiarism and data theft machines will continue to plagiarize and steal data until the whole apparatus is a hall of mirrors.
Every body clap your hands. 👏👏👏👏👏👏👏👏👏👏👏👏👏👏👏
How low can you go?
Can you go down low?
All the way to the floor?
📉
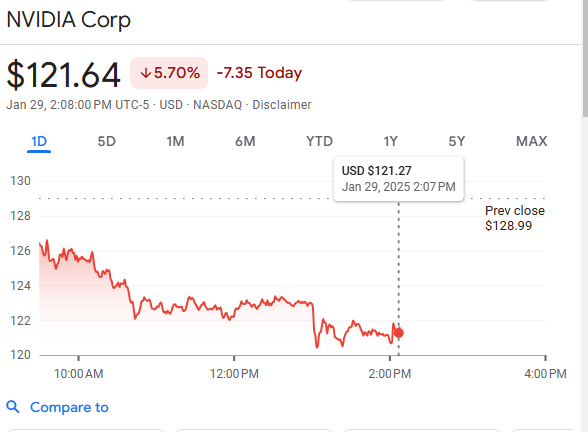
Cha Cha real smooth
NOOOOO!!! MY BOSS’S FORTUNE!!! GONE!!! WONT ANYBODY DO SOMETHING TO STOP THIS MADNESS?!? MY BOSS WORKS VERY HARD AT MAKING ME WORK HARD SO HE CAN HAVE ALL THE MONEY MY LABOR PRODUCES!!! CANT THE GOVERNMENT STEP IN AND BAIL HIM OUT?!? I’LL TAKE A PAYCUT!!! TWO PAYCUTS!!! I’LL WORK FOR FREE!!! PLEASE JUST WONT SOMEBODY THINK OF MY BOSS’S FORTUNE?!? 😭😭😭

Pippin: But what about a new AI model?
Aragorn: You already have one.
Pippin: We have one, yes. But what about a second AI model?
Alibaba? The website I bought a repair kit for 2$ that customs wanted to charge me 30$ for? That one? Impossible
And now they’ll have an AI to send you more spam emails lol
Holy shit this is not a bit
Can’t wait for Temu to reveal they’ve managed to run an even more efficient AI on this

lol, lmao even
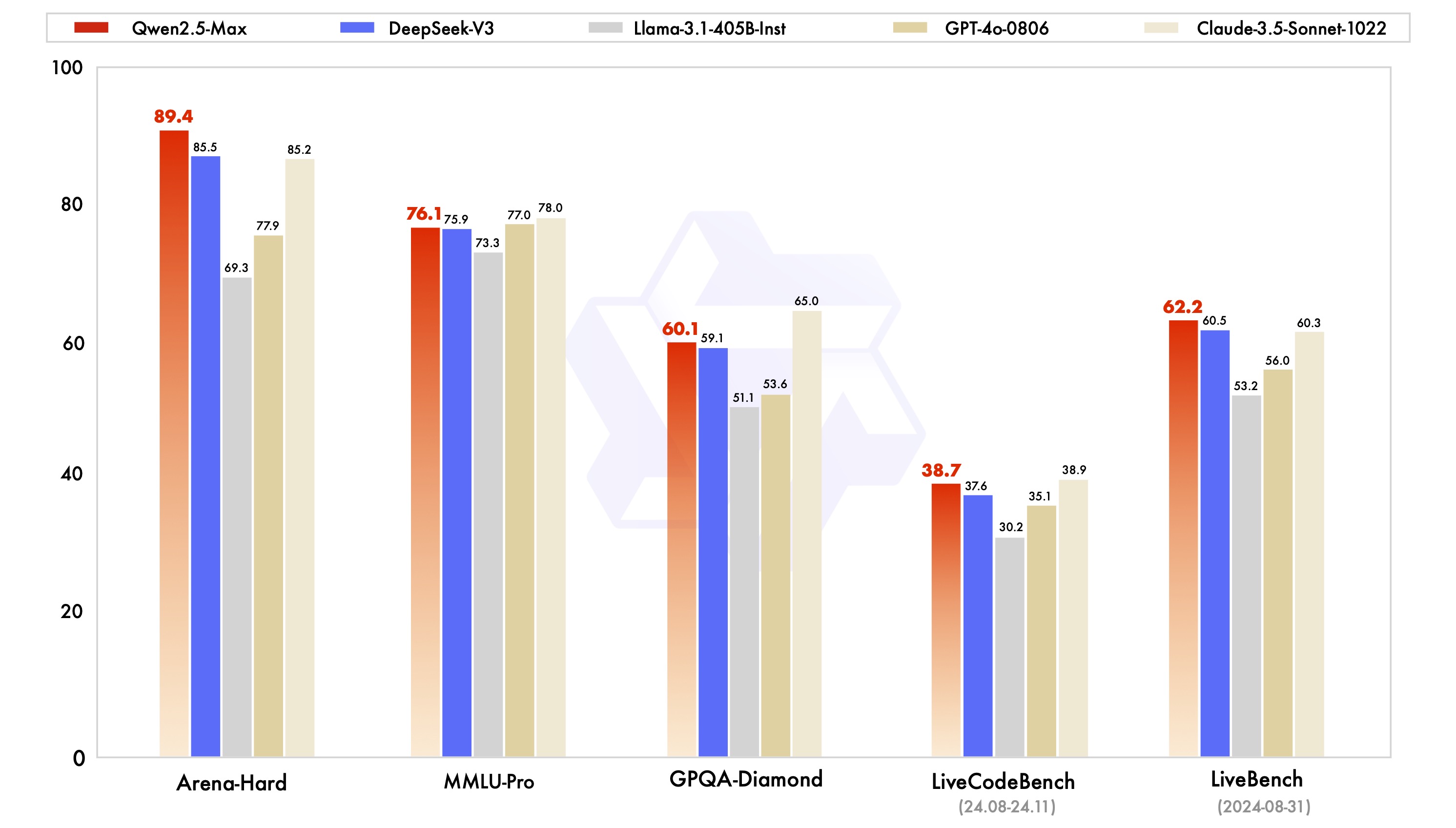
Not open source (at least at the moment), you can play with it hereSo they compared it to Deepseek-V3, not the more advanced R1.
“500: Internal Error”
guessing the feds took it down
Odd, the link works for me. archive.org link might work?
copy/paste of the release
Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model

It is widely recognized that continuously scaling both data size and model size can lead to significant improvements in model intelligence. However, the research and industry community has limited experience in effectively scaling extremely large models, whether they are dense or Mixture-of-Expert (MoE) models. Many critical details regarding this scaling process were only disclosed with the recent release of DeepSeek V3. Concurrently, we are developing Qwen2.5-Max, a large-scale MoE model that has been pretrained on over 20 trillion tokens and further post-trained with curated Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) methodologies. Today, we are excited to share the performance results of Qwen2.5-Max and announce the availability of its API through Alibaba Cloud. We also invite you to explore Qwen2.5-Max on Qwen Chat!
Performance
We evaluate Qwen2.5-Max alongside leading models, whether proprietary or open-weight, across a range of benchmarks that are of significant interest to the community. These include MMLU-Pro, which tests knowledge through college-level problems, LiveCodeBench, which assesses coding capabilities, LiveBench, which comprehensively tests the general capabilities, and Arena-Hard, which approximates human preferences. Our findings include the performance scores for both base models and instruct models.
We begin by directly comparing the performance of the instruct models, which can serve for downstream applications such as chat and coding. We present the performance results of Qwen2.5-Max alongside leading state-of-the-art models, including DeepSeek V3, GPT-4o, and Claude-3.5-Sonnet.
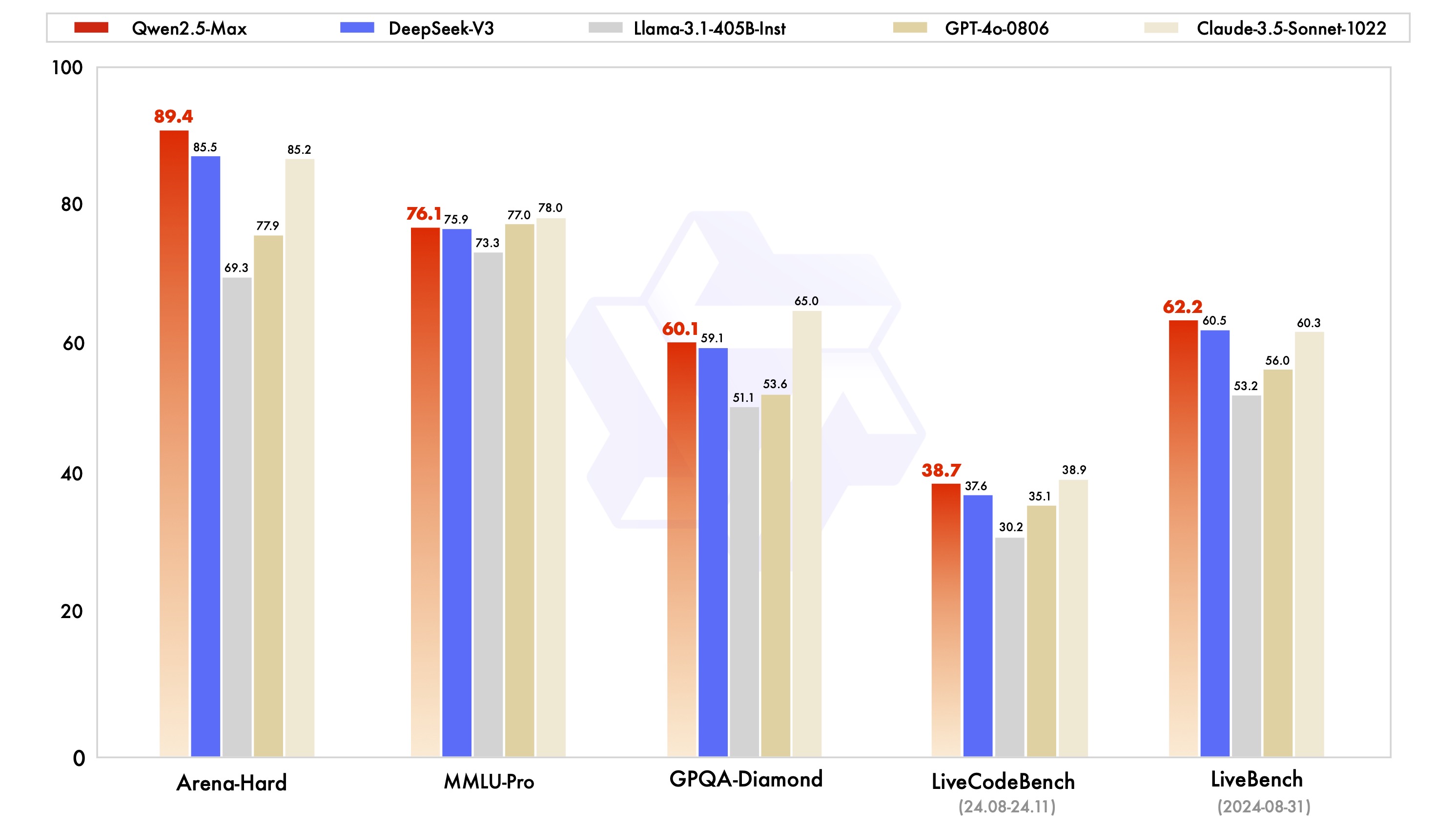
Qwen2.5-Max outperforms DeepSeek V3 in benchmarks such as Arena-Hard, LiveBench, LiveCodeBench, and GPQA-Diamond, while also demonstrating competitive results in other assessments, including MMLU-Pro.
When comparing base models, we are unable to access the proprietary models such as GPT-4o and Claude-3.5-Sonnet. Therefore, we evaluate Qwen2.5-Max against DeepSeek V3, a leading open-weight MoE model, Llama-3.1-405B, the largest open-weight dense model, and Qwen2.5-72B, which is also among the top open-weight dense models. The results of this comparison are presented below.

Our base models have demonstrated significant advantages across most benchmarks, and we are optimistic that advancements in post-training techniques will elevate the next version of Qwen2.5-Max to new heights.
Use Qwen2.5-Max
Now Qwen2.5-Max is available in Qwen Chat, and you can directly chat with the model, or play with artifacts, search, etc.
The API of Qwen2.5-Max (whose model name is qwen-max-2025-01-25) is available. You can first register an Alibaba Cloud account and activate Alibaba Cloud Model Studio service, and then navigate to the console and create an API key.
Since the APIs of Qwen are OpenAI-API compatible, we can directly follow the common practice of using OpenAI APIs. Below is an example of using Qwen2.5-Max in Python:
Future Work
The scaling of data and model size not only showcases advancements in model intelligence but also reflects our unwavering commitment to pioneering research. We are dedicated to enhancing the thinking and reasoning capabilities of large language models through the innovative application of scaled reinforcement learning. This endeavor holds the promise of enabling our models to transcend human intelligence, unlocking the potential to explore uncharted territories of knowledge and understanding.
tried it on my phone and it works. doesn’t like my laptop i guess for some reason

😌
Qwen has always been a good model. I’m excited to see how it runs, especially
qwen-2.5-max-coder-instruct:14bif it exists


















