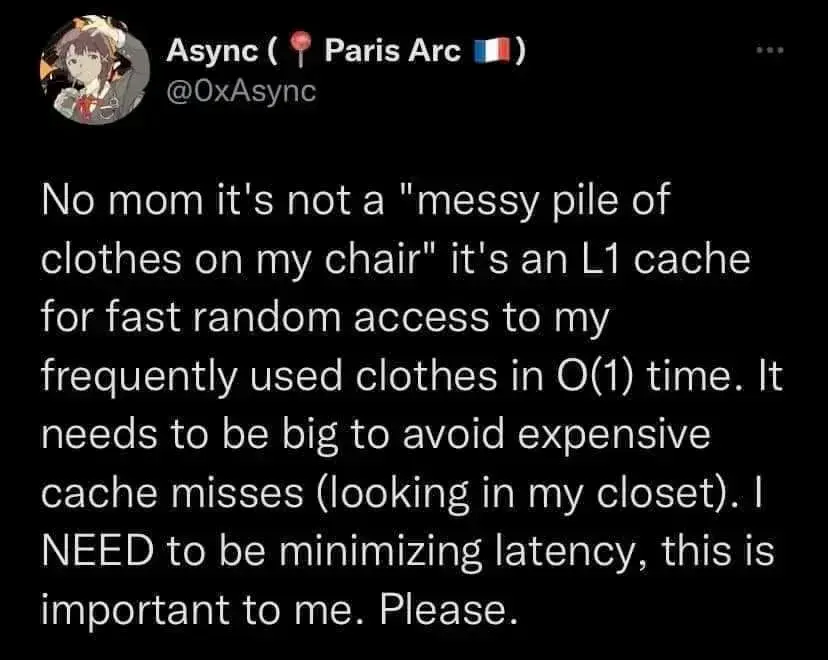
Why would you use a pile out of all data structures, only adding is in ϴ(1), searching is in ϴ(n).
I suggest throwing the clothes on the floor and remembering the spot they landed on. That’s ϴ(1) for adding and for searching, far superior to a stack of clothes on a chair.
Side note: fuck big O notation, use big ϴ notation >:(
i think that’s the point, it’s not a “messy pile”, it’s actually a completely organized cache; depending on the replacement policy it can appear messy, but you keep the offset and address stored locally for fast access and more hits (i remember that i put some arguably clean socks somewhere in the corner over there)
Ok, I didn’t understand roughly half of your comment because I don’t actually know how cache works in practice
BUT
a messy pile of clothes represents a stack, doesn’t it? And a stack makes a horrible cache because unlike a simple array you don’t have fast random access. You’d have to dig through the entire pile of clothes to get to the bottom which takes a lot of time.
Thay depends on the size of the pile, there could be a lot of weight and instability above the pants and you’ll have to pull them out à la Jenga or carefully rearrange the stack.
Since the amount of rearranging increases for larger n (imagine a pile reaching the ceiling), searching is in ω(1).
Well, there’s only finitely many atoms in the universe, do all algorithms therefore have constant time?
Although you could argue for very large amounts of clothes my method of throwing clothes on the floor starts performing worse due to clothes falling on the same spot and piling up again.
Unless you extend your room. Let’s take a look at the ✨amortized✨time complexity.
Well landau notation only describes the behaviour as an input value tends to infinty, so yes, every real machine with constant finite memory will complete everything in constant time or loop forever, as it can only be in a finite amount of states.
Luckily, even if our computation models (RAM/TM/…) assume infinite memory, for most algorithms the asymptotic behaviour is describing small-case behaviour quite well.
But not always, e.g. InsertionSort is an O(n^2) algorithm, but IRL much faster than O(n log n) QuickSort/MergeSort, for n up to 7 or so. This is why in actual programs hybrid algorithms are used.
A cache is not a stack, it’s memory stored in parallel cells. The CPU could theoretically, depending on the implementation, directly find the data it’s looking for by going to the address of the cell it remembers that it’s in.
Not all L1 caches operate the same, but in almost all cases, it’s easy to actually go and get the data no matter where it physically is. If the data is at address 0 or at address 512, they both take the same time to fetch. The problem is if you don’t know where the data is, in which case you have to use heuristics to guess where it might be, or in the worst case check absolutely everywhere in the cache only to find it at the very last place… or the data isn’t there at all. In which case you’d check L2 cache, or RAM. The whole purpose of a cache is to randomly store data there that the CPU thinks it might need again in the future, so fast access is key. And in the most ideal case, it could theoretically be done in O(1).
ETA: I don’t personally work with CPUs so I could be very wrong, but I have taken a few CPU architecture classes.
I think the previous commenters point was that to get to something at the bottom of a pile of clothes, even if you know where it is, you have to move everything from on top of it, like a stack.

{kind=link}
Why would you use a pile out of all data structures, only adding is in ϴ(1), searching is in ϴ(n).
I suggest throwing the clothes on the floor and remembering the spot they landed on. That’s ϴ(1) for adding and for searching, far superior to a stack of clothes on a chair.
Side note: fuck big O notation, use big ϴ notation >:(
i think that’s the point, it’s not a “messy pile”, it’s actually a completely organized cache; depending on the replacement policy it can appear messy, but you keep the offset and address stored locally for fast access and more hits (i remember that i put some arguably clean socks somewhere in the corner over there)
Ok, I didn’t understand roughly half of your comment because I don’t actually know how cache works in practice
BUT
a messy pile of clothes represents a stack, doesn’t it? And a stack makes a horrible cache because unlike a simple array you don’t have fast random access. You’d have to dig through the entire pile of clothes to get to the bottom which takes a lot of time.
Not necessarily. If you know that your pants are at the bottom then you can just plunge your hand into the pile and grab them without any searching.
Thay depends on the size of the pile, there could be a lot of weight and instability above the pants and you’ll have to pull them out à la Jenga or carefully rearrange the stack.
Since the amount of rearranging increases for larger n (imagine a pile reaching the ceiling), searching is in ω(1).
I feel like this metaphor is getting out of hand
As the volume of the room is finite, even “exponential” or worse search algorithms will complete in constant time.
<.<
Well, there’s only finitely many atoms in the universe, do all algorithms therefore have constant time?
Although you could argue for very large amounts of clothes my method of throwing clothes on the floor starts performing worse due to clothes falling on the same spot and piling up again.
Unless you extend your room. Let’s take a look at the ✨amortized✨time complexity.
Well landau notation only describes the behaviour as an input value tends to infinty, so yes, every real machine with constant finite memory will complete everything in constant time or loop forever, as it can only be in a finite amount of states.
Luckily, even if our computation models (RAM/TM/…) assume infinite memory, for most algorithms the asymptotic behaviour is describing small-case behaviour quite well.
But not always, e.g. InsertionSort is an O(n^2) algorithm, but IRL much faster than O(n log n) QuickSort/MergeSort, for n up to 7 or so. This is why in actual programs hybrid algorithms are used.
A cache is not a stack, it’s memory stored in parallel cells. The CPU could theoretically, depending on the implementation, directly find the data it’s looking for by going to the address of the cell it remembers that it’s in.
Not all L1 caches operate the same, but in almost all cases, it’s easy to actually go and get the data no matter where it physically is. If the data is at address 0 or at address 512, they both take the same time to fetch. The problem is if you don’t know where the data is, in which case you have to use heuristics to guess where it might be, or in the worst case check absolutely everywhere in the cache only to find it at the very last place… or the data isn’t there at all. In which case you’d check L2 cache, or RAM. The whole purpose of a cache is to randomly store data there that the CPU thinks it might need again in the future, so fast access is key. And in the most ideal case, it could theoretically be done in O(1).
ETA: I don’t personally work with CPUs so I could be very wrong, but I have taken a few CPU architecture classes.
I think the previous commenters point was that to get to something at the bottom of a pile of clothes, even if you know where it is, you have to move everything from on top of it, like a stack.
Huh, TIL about big theta
There’s also big omega (lower bound)
what’s the difference?