
yeah with what other people have said it’s most likely bad or unseated RAM
- 6 Posts
- 60 Comments
Joined 1 year ago
Cake day: July 9th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.



 3·5 months ago
3·5 months agocurrently, yes, but this is more an investigation into how well a neural network could play a bullet hell game
very few bullet hell AI programs rely on machine learning and virtually all of the popular ones use algorithms.
but it is interesting to see how it mimics human behaviour, skills and strategies and how different methods of machine learning perform and why
(plus I understand machine learning more than the theory behind those bullet hell bots.)
the training environment is pretty basic right now so all bullets shoot from the top of the screen with no enemy to destroy.
additionally, the program I’m using to get player and bullet data (twinject) doesn’t support enemy detection so the neural network wouldn’t be able to see enemies in an existing bullet hell game. the character used has a wide bullet spread and honing bullets so the neural network inadvertently destroys the enemies on screen.
the time spent in each training session is constant rather than dependent on survival time because the scoring system is based on the total bullet distance only.
definitely. usually algorithms are used to calculate the difficulty of a game (eg. in osu!, a rhythm game) so there’s definitely a practical application there
one problem ive seen with these game ai projects is that you have to constantly tweak it and reset training because it eventually ends up in a loop of bad habits and doesnt progress
you’re correct that this is a recurring problem with a lot of machine learning projects, but this is more a problem with some evolutionary algorithms (simulating evolution to create better-performing neural networks) where the randomness of evolution usually leads to unintended behaviour and an eventual lack of progression, while this project instead uses deep Q-learning.
the neural network is scored based on its total distance between every bullet. so while the neural network doesn’t perform well in-game, it does actually score very good (better than me in most attempts).
so is it even possible to complete such a project with this kind of approach as it seems to take too much time to get anywhere without insane server farms?
the vast majority of these kind of projects - including mine - aren’t created to solve a problem. they just investigate the potential of such an algorithm as a learning experience and for others to learn off of.
the only practical applications for this project would be to replace the “CPU” in 2 player bullet hell games and maybe to automatically gauge a game’s difficulty and programs already exist to play bullet hell games automatically so the application is quite limited.

the body of the post has the ringtone attached. I might need to edit it to make it viewable through Photon but you can also view it on a browser
I always find it interesting to see how optimization algorithms play games and to see how their habits can change how we would approach the game.
me too! there aren’t many attempts at machine learning in this type of game so I wasn’t really sure what to expect.
Humans would usually try to find the safest area on the screen and leave generous amounts of space in their dodges, whereas the AI here seems happy to make minimal motions and cut dodges as closely as possible.
yeah, the NN did this as well in the training environment. most likely it just doesn’t understand these tactics as well as it could so it’s less aware of (and therefore more comfortable) to make smaller, more riskier dodges.
I also wonder if the AI has any concept of time or ability to predict the future.
this was one of its main weaknesses. the timespan of the input and output data are both 0.1 seconds - meaning it sees 0.1 seconds into the past to perform moves for 0.1 seconds into the future - and that amount of time is only really suitable for quick, last-minute dodges, not complex sequences of moves to dodge several bullets at a time.
If not, I imagine it could get cornered easily if it dodges into an area where all of its escape routes are about to get closed off.
the method used to input data meant it couldn’t see the bounds of the game window so it does frequently corner itself. I am working on a different method that prevents this issue, luckily.
I did create a music NN and started coding an UNO NN, but apart from that, no
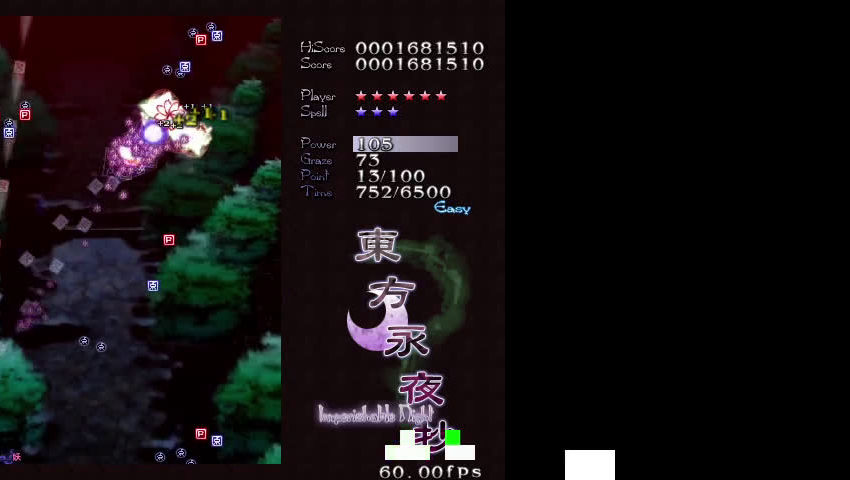
yeah, the training environment was a basic bullet hell “game” (really just bullets being fired at the player and at random directions) to teach the neural network basic bullet dodging skills

- the white dot with 2 surrounding squares is the player and the red dots are bullets
- the data input from the environment is at the top-left and the confidence levels for each key (green = pressed) are at the bottom-left
- the scoring system is basically the total of all bullet distances
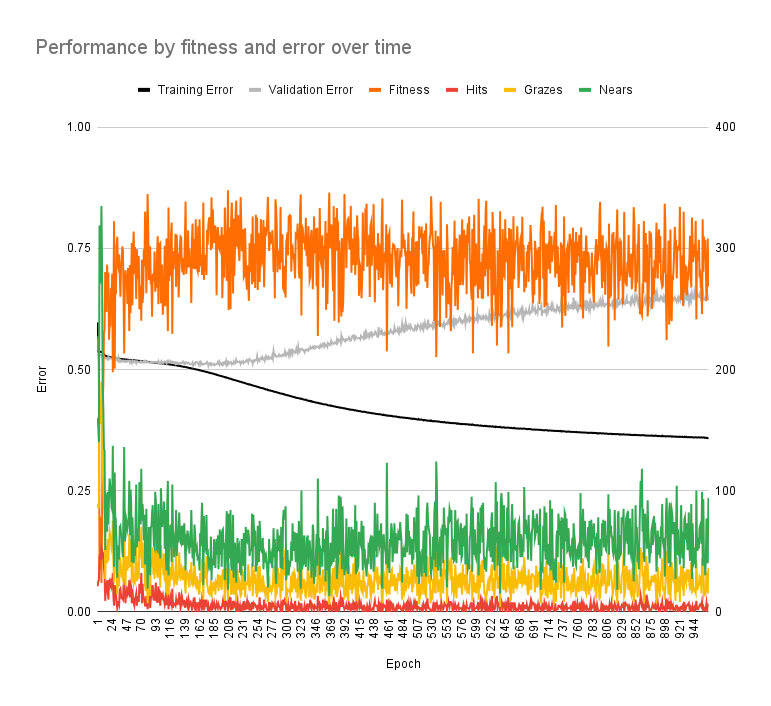
- this was one of the training sessions
- the fitness does improve but stops improving pretty quickly
- the increase in validation error (while training error decreased) is indicated overfitting
- it’s kinda hard to explain here but basically the neural network performs well with the training data it is trained with but doesn’t perform well with training data it isn’t (which it should also be good at)
 1·6 months ago
1·6 months agolol I understand the feeling
thanks for this!! there’s so much info on this comment
i’m currently using Logseq w/ Syncthing but i’ll be looking at Org Mode and DokuWiki
 45·7 months ago
45·7 months agothis is the ad-free version, which is available with the exact same (if I’m correct) features on F-Droid for free, along with the source code on GitHub.
the versions on the Play Store (paid version and free version with ads) likely just help pay the developer for their work
and as others have said already, free software is free as in freedom, not free beer.
oh, I forgot about the API not being freely available; so an alternate frontend wouldn’t be a proper solution?
going by the other comments, though, there are client-side options that can avoid API issues entirely by just re-styling the webpage. thanks for the info, though!
yeah, that was the main reason I wanted to apply it to old Reddit specifically, because it would have been easier with simpler theming and old Reddit is close to Lemmy’s style too
I installed RES beforehand, but haven’t used any of its features. I’ll try this out first and maybe Stylish if that doesn’t work. thanks!
okay thanks for the tip! I’m already using Stylish but I couldn’t find a pre-made style for Lemmy.
I figured I could make my own but I didn’t want to waste time doing something that could have been done already or could be done faster. at least I know I’m on the right track!
yeah, my bad. edited the comment with more accurate info
and this does apply to creative writing, not knowledgeable stuff like coding

{kind=link}
that’s good then! i had this same issue (randomly freezing after turning it om for some time) though new RAM ended up fixing it